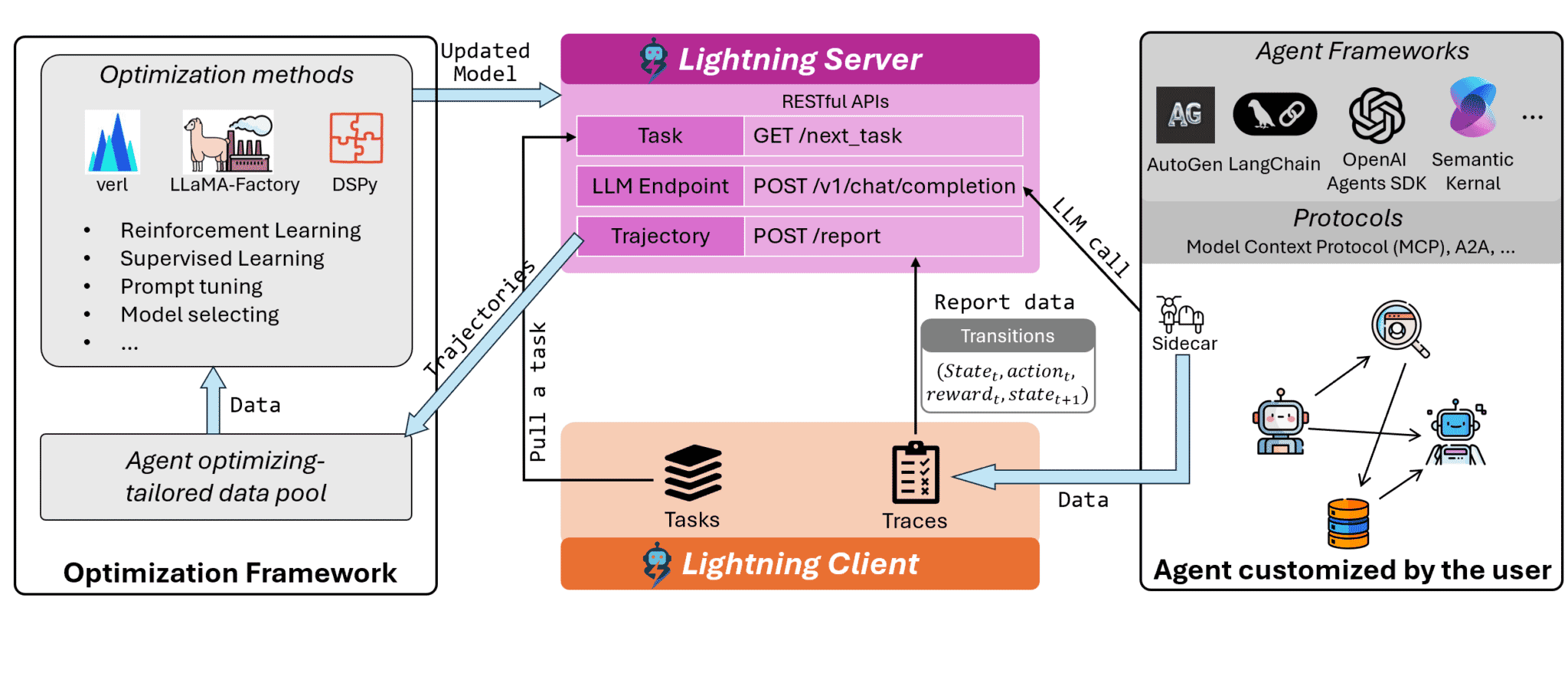
Agent Lightning isn’t brand new, it’s a 2025 Microsoft Research project that’s been maturing over this year, but it’s something that recently landed on my radar and immediately clicked with how I think about agents. At a high level, it’s a framework‑agnostic “trainer layer” that lets you plug RL‑style optimization into almost any existing agent stack with minimal code changes.
What Agent Lightning actually does
- It decouples agent workflow from training: your agents keep running on LangChain, OpenAI Agents SDK, AutoGen, etc., while Lightning’s server + client collect traces and feed them into RL training.
- Those traces are turned into transition tuples and optimized with backends like verl, so the underlying model improves based on real interactions instead of offline toy datasets.
- Because it talks via an OpenAI‑compatible API and sidecar design, you can drop it next to your existing agent infrastructure instead of rewriting workflows.
Why it’s interesting to me
For anyone building production agents (ads, analytics, workflows), this feels like a clean way to bolt on learning and continuous improvement without marrying a single agent framework. It also lines up nicely with the kind of RL‑flavoured, framework‑agnostic agent systems I’m trying to explore and share more of over the coming months.